I use Horizon Data everyday, and it really
is amazing how easy it is to work with. However, maybe it’s my storage
background, but I can’t help but wonder what happens to my file after I’ve
uploaded it into my Horizon Data folder.
Where does it go?
Horizon Data is integrated into Horizon
Workspace – which means that it’s part of the Workspace vApp.

The Horizon Data VM, which obviously
handles the Files / Data side of things in workspace, includes several VMDKs
(which are, fortunately, thin provisioned).
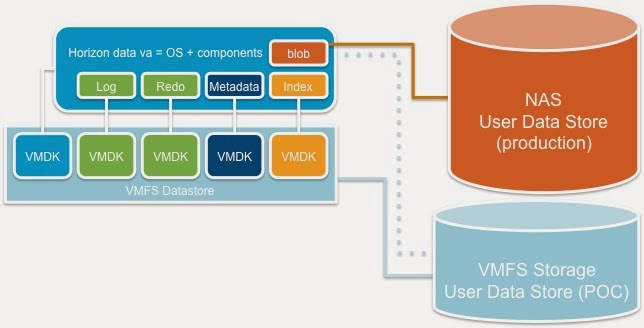
If you’re running a small-scale deployment
(e.g. an evaluation or demo environment), you can stick with the default
configuration of having Horizon Data store things inside the VMDKs.
In production environments, however, it is
recommended to use NFS storage for Horizon Data (how to add an NFS mount is
documented here).
It’s worth noting that this NFS volume will
be mounted into the VM, not to the ESXi Host(s).
This means that the NFS traffic will be
using the VM Network that the Horizon Data VM is connected to, rather than a
VMKernel connection to the ESXi Hosts – so it’s worth considering whether this
network will have connectivity to your NFS storage array as well as how much
available bandwidth / performance there will be for NFS traffic on that
network.
In any case, they key thing to bear in mind
is that Horizon Data uses a mysql database to index the files that users
upload. Mysql then stores these files as Blobs.
What is a Blob?
 |
| Image courtesy of wikipedia |
A Blob is a Binary Large Object, which is
basically a method for storing pretty much any kind of file within a table in a
database.
To me, this makes a lot of sense – rather
than having unstructured data scattered around a filesystem, the database keeps
everything neat & tidy.
I like to think of it like this…back in
2002, I converted most of my CD collection into MP3s, and went to a lot of
trouble to keep my MP3 files organized – each artist had a folder, and inside
there was a folder for each album.
I started off with about 5GB of Music,
which was probably like 30 folders of stuff. At the time, I used to browse
through the folders, find things I wanted to listen to, then drag them into a
music player (I was a big fan of WinAmp!).
11 years later, and I now have nearly 40GB
of Music. I’ve been through 6 laptops in that time, and 3 USB hard drives.
The last time I looked at my Music folder,
it was a mess. There was a bunch of duplicate files & folders, things in
the wrong place, things missing (some laptop migrations were a result of hard
drive failures!).
So, browsing through the folders and
dragging things into a music player just doesn’t work.
 The last time I migrated my laptop,
rather than copy the files over myself, I used iTunes to import everything,
with these 2 options set:
The last time I migrated my laptop,
rather than copy the files over myself, I used iTunes to import everything,
with these 2 options set:
Now, I see all my music in one place, and
click on whatever I want to play. I don’t care where iTunes stores each file.
If & when I need to migrate off this laptop, I’ll just Export my iTunes
Library.
So, getting back to Horizon Data.
Here’s a file I made earlier, and uploaded
into my Horizon Data folder.

If I log into the Horizon Data VM (as root),
I can navigate through to the directory where the blobs are stored
(/opt/zimbra/store).
Inside that directory, mysql has structured
things very carefully. Here’s what the blob looks like:

The path, as well as the filename are both
important. AFAIK they relate to tablespaces etc within the database, I’m sure
someone who understands mysql better than I do can tell you all about it.
If I look at that .msg file, you can see
it’s actually the .txt file I uploaded into my Horizon folder.
So, Horizon Data has changed the filename
& extension, and manages it’s own directory structure to store things, but
the actual content of my file hasn’t been modified.
From a storage perspective, this means that
any block based deduplication should work very well for files stored by Horizon
Data.
File based single instancing (leaving
behind stub files etc) wouldn’t be a good idea, but anything block based which
is invisible to the filesystem and preserves the file & directory structure
should work very well at freeing up disk space.
I’d be very interested to see someone do
some testing with this & see what kind of dedupe ratios they achieve.










